





Pod Disruptions
Hai semuanya, sebelumnya kita sudah membahas secara detail tentang Pod Specification selanjutnya jika kita mau membuat aplikasi yang support dengan Highly Available containers pada kubernetes kita harus memahami System yang namanya Distruption dan juga beberapa cluster administration upgrading and autoscaling clusters.
So karena pembahasannya ini akan lumayan panjang jadi kita akan bagi-bagi menjadi beberapa bagian diantaranya:
- Voluntary and involuntary disruptions
- Pod disruption budgets
- Pod disruption conditions
Ok tanpa berlama-lama yuk lansung aja kita bahas materi yang pertama:
Voluntary and involuntary disruptions
Meskipun kubernetes system terlihat sudah sempurna dan matang (mature), tetapi posibility failure masih bisa terjadi lohh, salah satunya adalah voluntary dan involuntary distruption.
Mungkin dari temen-temen ada yang binggung apa sih magsudnya voluntary dan involuntary distruption?
Jadi meskipun feature unggulan dari kubernetes adalah HA (High Availables) tapi memang tidak bisa dipungkiri yang namanya system pasti tidak akan ada yang sempurna, baik software maupun hardware pasti ada celahnya (distruption). Failure system pada distruption bisa saja di sebabkan secara di sengaja (voluntary) dan juga tidak di sengaja (involuntary) ok kita bahas satu-per-satu dari involuntary distruption.
Pods do not disappear until someone (a person or a controller) destroys them, or there is an unavoidable hardware or system software error.
We call these unavoidable cases involuntary disruptions to an application. Examples are:
- a hardware failure of the physical machine backing the node
- cluster administrator deletes VM (instance) by mistake
- cloud provider or hypervisor failure makes VM disappear
- a kernel panic
- the node disappears from the cluster due to cluster network partition
- eviction of a pod due to the node being out-of-resources.
Except for the out-of-resources condition, all these conditions should be familiar to most users; they are not specific to Kubernetes.
We call other cases voluntary disruptions. These include both actions initiated by the application owner and those initiated by a Cluster Administrator.
Typical application owner actions include:
- Deleting the deployment or other controller that manages the pod
- Updating a deployment’s pod template causing a restart
- Directly deleting a pod (e.g. by accident)
Cluster administrator actions include:
- Draining a node for repair or upgrade.
- Draining a node from a cluster to scale the cluster down (learn about Cluster Autoscaling).
- Removing a pod from a node to permit something else to fit on that node.
These actions might be taken directly by the cluster administrator, or by automation run by the cluster administrator, or by your cluster hosting provider.
Here are some ways to mitigate involuntary disruptions:
- Ensure your pod requests the resources it needs.
- Replicate your application if you need higher availability. (using replicated stateless and stateful applications)
- For even higher availability when running replicated applications, spread applications across racks (using anti-affinity) or across zones (if using a multi-zone cluster).
The frequency of voluntary disruptions varies. On a basic Kubernetes cluster, there are no automated voluntary disruptions (only user-triggered ones). However, your cluster administrator or hosting provider may run some additional services which cause voluntary disruptions. For example, rolling out node software updates can cause voluntary disruptions. Also, some implementations of cluster (node) autoscaling may cause voluntary disruptions to defragment and compact nodes. Your cluster administrator or hosting provider should have documented what level of voluntary disruptions, if any, to expect. Certain configuration options, such as using PriorityClasses in your pod spec can also cause voluntary (and involuntary) disruptions.
Pod disruption budgets
Kubernetes offers features to help you run highly available applications even when you introduce frequent voluntary disruptions.
As an application owner, you can create a PodDisruptionBudget (PDB) for each application. A PDB limits the number of Pods of a replicated application that are down simultaneously from voluntary disruptions. For example, a quorum-based application would like to ensure that the number of replicas running is never brought below the number needed for a quorum. A web front end might want to ensure that the number of replicas serving load never falls below a certain percentage of the total.
Cluster managers and hosting providers should use tools which respect PodDisruptionBudgets by calling the Eviction API instead of directly deleting pods or deployments.
For example, the kubectl drain subcommand lets you mark a node as going out of service. When you run kubectl drain, the tool tries to evict all of the Pods on the Node you’re taking out of service. The eviction request that kubectl submits on your behalf may be temporarily rejected, so the tool periodically retries all failed requests until all Pods on the target node are terminated, or until a configurable timeout is reached.
A PDB specifies the number of replicas that an application can tolerate having, relative to how many it is intended to have. For example, a Deployment which has a .spec.replicas: 5 is supposed to have 5 pods at any given time. If its PDB allows for there to be 4 at a time, then the Eviction API will allow voluntary disruption of one (but not two) pods at a time.
for Examples
Consider a cluster with 3 nodes, node-1 through node-3. The cluster is running several applications. One of them has 3 replicas initially called pod-a, pod-b, and pod-c. Another, unrelated pod without a PDB, called pod-x, is also shown. Initially, the pods are laid out as follows:
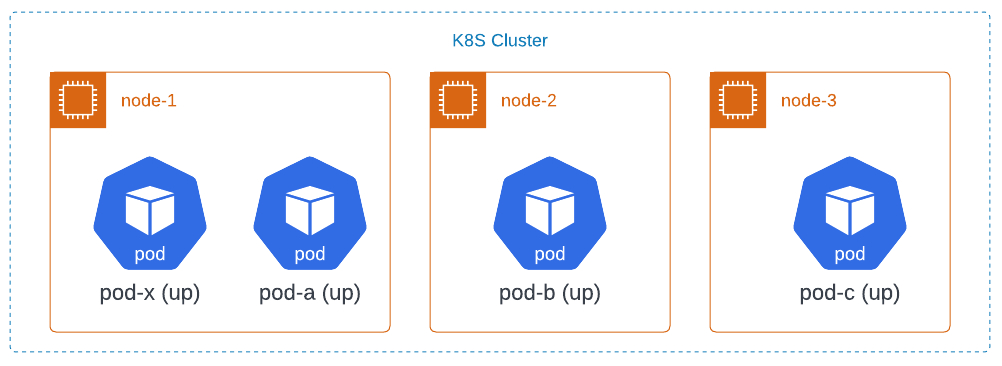
All 3 pods are part of a deployment, and they collectively have a PDB which requires there be at least 2 of the 3 pods to be available at all times.
For example, assume the cluster administrator wants to reboot into a new kernel version to fix a bug in the kernel. The cluster administrator first tries to drain node-1 using the kubectl drain command. That tool tries to evict pod-a and pod-x. This succeeds immediately. Both pods go into the terminating state at the same time. This puts the cluster in this state:
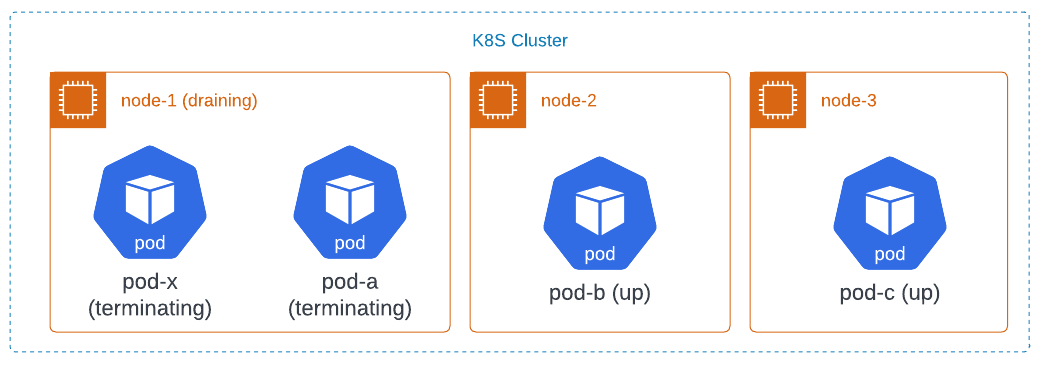
The deployment notices that one of the pods is terminating, so it creates a replacement called pod-d. Since node-1 is cordoned, it lands on another node. Something has also created pod-y as a replacement for pod-x.
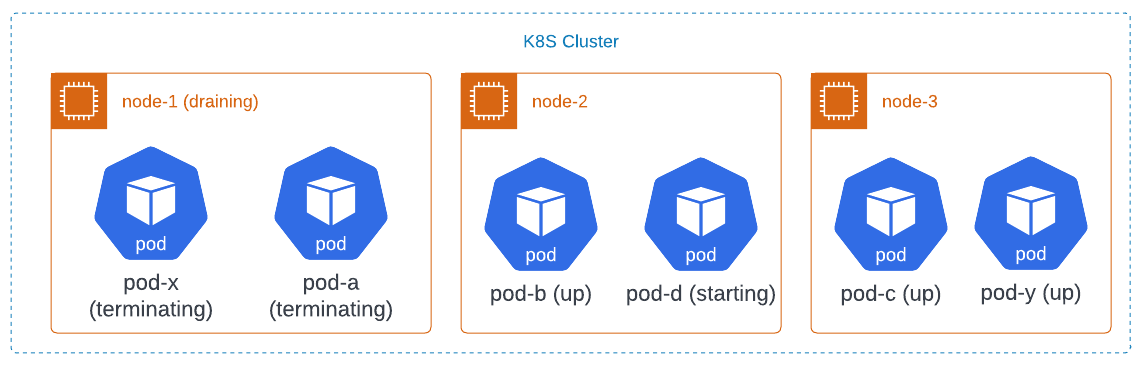
At some point, the pods terminate, and the cluster looks like this:
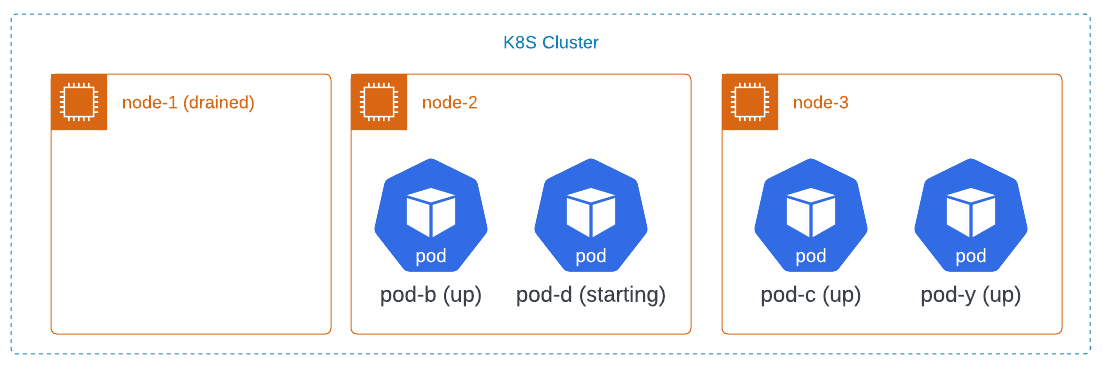
Now, the cluster administrator tries to drain node-2. The drain command will try to evict the two pods in some order, say pod-b first and then pod-d. It will succeed at evicting pod-b. But, when it tries to evict pod-d, it will be refused because that would leave only one pod available for the deployment.
The deployment creates a replacement for pod-b called pod-e. Because there are not enough resources in the cluster to schedule pod-e the drain will again block. The cluster may end up in this state:
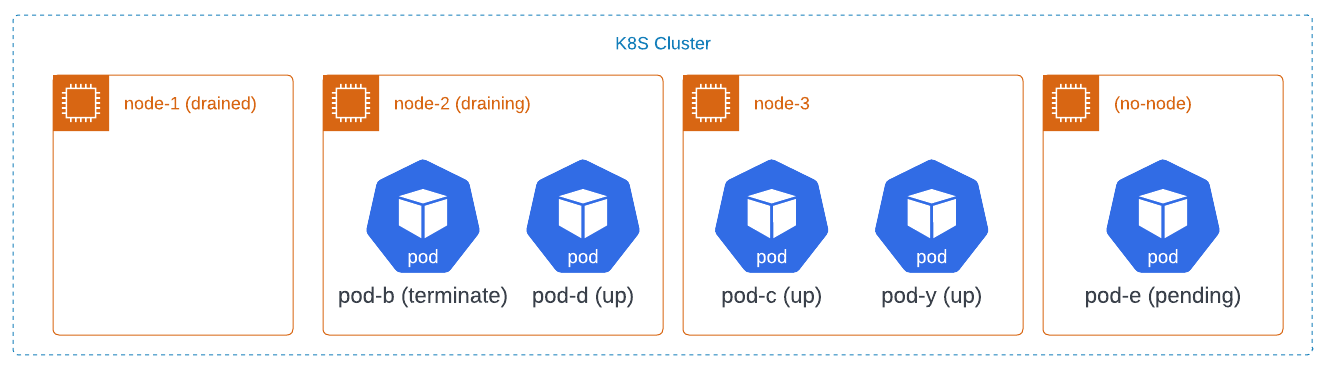
At this point, the cluster administrator needs to add a node back to the cluster to proceed with the upgrade.
You can see how Kubernetes varies the rate at which disruptions can happen, according to:
- how many replicas an application needs
- how long it takes to gracefully shutdown an instance
- how long it takes a new instance to start up
- the type of controller
- the cluster’s resource capacity
Pod disruption conditions
Note: In order to use this behavior, you must enable the PodDisruptionConditions feature gate in your cluster.
When enabled, a dedicated Pod DisruptionTarget condition is added to indicate that the Pod is about to be deleted due to a disruption. The reason field of the condition additionally indicates one of the following reasons for the Pod termination:
PreemptionByKubeScheduler, Pod is due to be preempted by a scheduler in order to accommodate a new Pod with a higher priority.DeletionByTaintManager, Pod is due to be deleted by Taint Manager (which is part of the node lifecycle controller withinkube-controller-manager) due to aNoExecutetaint that the Pod does not tolerate; see taint-based evictions.EvictionByEvictionAPI, Pod has been marked for eviction using the Kubernetes API.DeletionByPodGC, Pod, that is bound to a no longer existing Node, is due to be deleted by Pod garbage collection.
Note: A Pod disruption might be interrupted. The control plane might re-attempt to continue the disruption of the same Pod, but it is not guaranteed. As a result, the DisruptionTarget condition might be added to a Pod, but that Pod might then not actually be deleted. In such a situation, after some time, the Pod disruption condition will be cleared.
When using a Job (or CronJob), you may want to use these Pod disruption conditions as part of your Job’s Pod failure policy.